Abstract
Semantic segmentation in adverse weather scenarios is a critical task for autonomous driving systems. While foundation models have shown promise, the need for specialized adaptors becomes evident for handling more challenging scenarios.
We introduce DiffPrompter, a novel differentiable visual and latent prompting mechanism aimed at expanding the learning capabilities of existing adaptors in foundation models. Our proposed ∇HFC image processing block excels particularly in adverse weather conditions, where conventional methods often fall short. Furthermore, we investigate the advantages of jointly training visual and latent prompts, demonstrating that this combined approach significantly enhances performance in out-of-distribution scenarios.
Our differentiable visual prompts leverage parallel and series architectures to generate prompts, effectively improving object segmentation tasks in adverse conditions. Through a comprehensive series of experiments and evaluations, we provide empirical evidence to support the efficacy of our approach.
Video
Overview
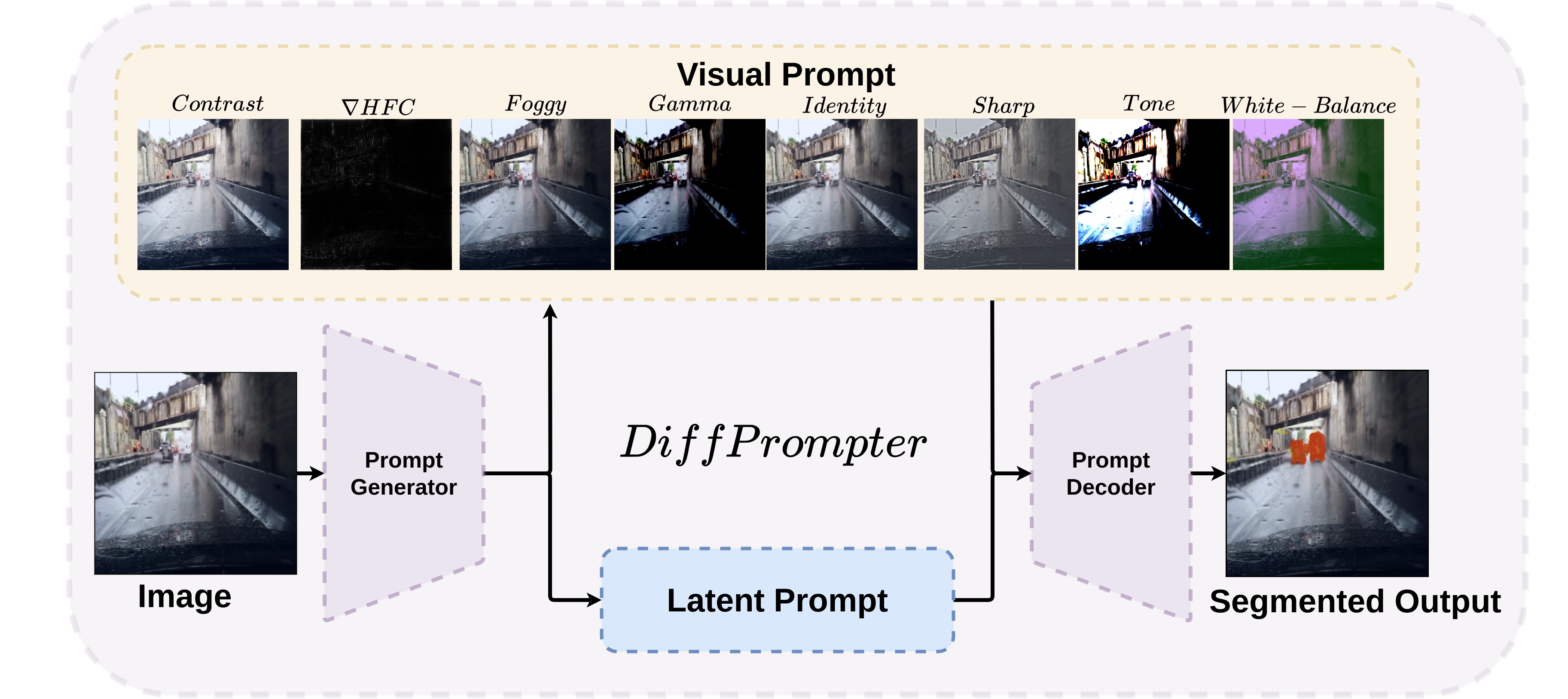
DiffPrompter is a semantic segmentation method that utilizes the visual and latent prompts generated by the prompt generator. These prompts are then used by the prompt decoder to generate a semantic mask for segmenting objects, especially in adverse conditions and low-level segmentation tasks.

The DiffPrompter framework serves as the inspiration for creating Serial Differentiable Adapter (SDA) and Parallel Differentiable Adapter (PDA), both of which achieve superior results as compared to the current state-of-the-art (SOTA) methods, EVP and SAM-Adapter.
On the left side of the vertical dashed line in the above figure, the columns respectively represent the ground-truth segmentation mask, the SAM-Adapter (ViT-B) output, and the PDA (SAM init.) output. In this representation, the model's masked output is shown in red, with green bounding boxes highlighting correct predictions and red bounding boxes indicating missed segmentation outputs (false negatives) or incorrect segmentation outputs (false positives). On the right side of the vertical dashed line, we showcase qualitative results for EVP (ViT-B) and our SDA model.
It is evident that our proposed methods, PDA and SDA, demonstrate superior qualitative performance compared to the SOTA methods, EVP and SAM-Adapter.
Architecture
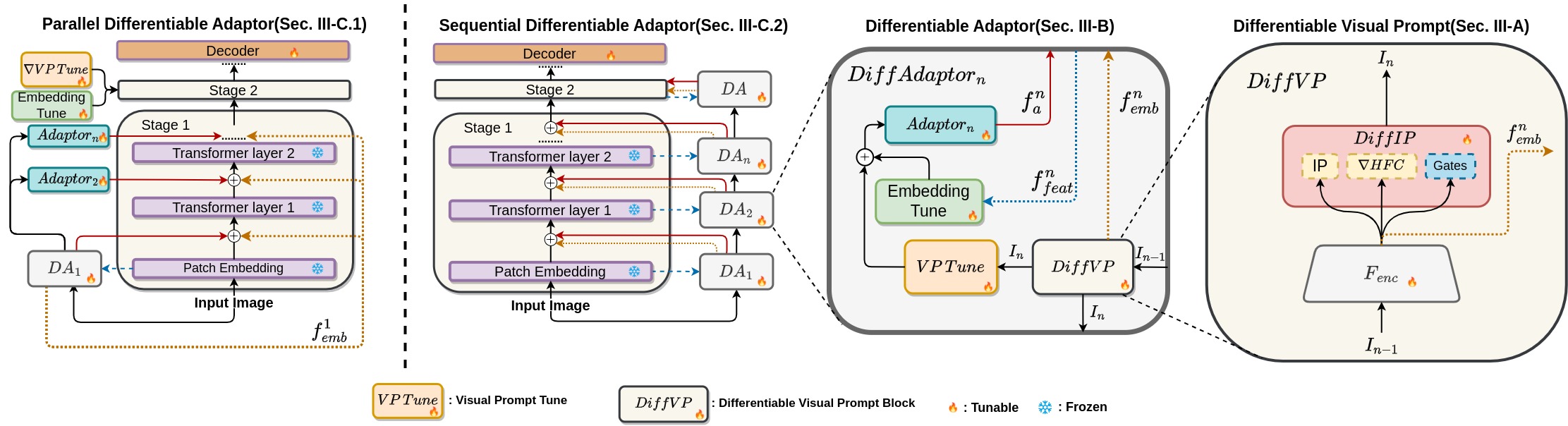
We propose a Differentiable Visual Prompt block, referred to as DiffVP, as shown in Sec. III-A. This block learns visual prompts using DiffIP and latent prompts through a shallow vision encoder.
The Differentiable Adaptor, denoted as DiffAdaptor (Sec. III-B), employs VPTune to learn the local information of the visual prompt. Local information from the transformer layer of the encoder is provided to the Embedding Tune layer. The output of the Embedding Tune and VPTune layers is combined and fed into the adaptor layer, which outputs local features that when added to the transformer layers, learn local invariant features.
To introduce global invariance in the features, the latent embedding generated by the shallow vision encoder is added to the transformer output features. This combination of local and global invariance aids the Parallel Differentiable Adaptor (Sec. III-C.1) and Sequential Differentiable Adaptor (Sec. III-C.2) in improving semantic segmentation tasks.
BibTeX
@article{diffprompter2023,
author = {Kalwar, Sanket and Ungarala, Mihir and Jain, Shruti and Monis, Aaron and Konda, Krishna Reddy and Garg, Sourav and Krishna, K Madhava},
title = {DiffPrompter: Differentiable Implicit Visual Prompts for Object-Segmentation in Adverse Conditions},
journal = {},
year = {2023},
}